
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Large language models (LLMs) show remarkable capabilities in solving complex problems through Chain-of-Thought (CoT) prompting, a technique that instructs the model to carefully break down the solution into concrete steps. Now, researchers are trying to find out whether foundation models for robots can benefit from the same kind of upgrade.
Researchers from the University of California, Berkeley, the University of Warsaw and Stanford University explore this question in their new paper, introducing “Embodied Chain-of-Thought Reasoning” (ECoT) for vision-language-action models (VLAs). ECoT enhances the decision-making capabilities of robot control systems by enabling them to reason about tasks, sub-tasks and their environment before taking action.
Reasoning in robotic control policies
The goal of robotic control policies is to enable robots to perform complex tasks autonomously. There has been a lot of progress in developing end-to-end control models, but they often fail when faced with novel situations that require reasoning and planning.
Vision-language-action models (VLAs) have emerged as a promising solution to creating more general-purpose robot control policies. VLAs build on the capabilities of pre-trained large vision-language models (VLMs) to map image observations and natural language instructions to robot actions. VLAs have achieved state-of-the-art performance for generalist robot policies and show impressive levels of generalization to new objects and scenes. Some notable examples include the open-source project OpenVLA and Google DeepMind’s RT-X-2.
However, current VLAs lack the reasoning capabilities of their LLM counterparts. They learn a direct mapping from observations to actions without intermediate reasoning steps.
Bringing chain-of-thought reasoning to VLAs
Chain-of-thought reasoning has proven to be very effective in improving the performance of LLMs on complex tasks. By generating intermediate steps, LLMs can better map the relationships between different parts of a problem and come up with more accurate solutions.
The researchers hypothesize that VLAs can get a performance boost “by training them to textually reason about their plan, environment, and motions, thereby allowing them to produce more accurate and robust robot actions.”
However, directly applying CoT techniques used in LLMs to robotics poses several challenges.
First, VLAs rely on relatively smaller, open-source VLMs that are not as good at reasoning as the larger LLMs used in language applications.
Second, robotic tasks require the model to reason not only about the task but also about the environment and the robot’s own state. Therefore, breaking down tasks into sub-tasks—the most common CoT technique in LLMs—is not enough for robotic applications. VLAs must ground their reasoning in their perception of the environment to make informed decisions about movements and manipulation.
“Put simply, we need VLAs to not only ‘think carefully’, but also ‘look carefully,’” the researchers write.
Embodied Chain-of-Thought (ECoT) reasoning
To overcome these challenges, the researchers have developed Embodied Chain-of-Thought (ECoT) reasoning for VLAs. ECoT enables robots to reason about their actions in a way that is grounded in their perception of the environment.
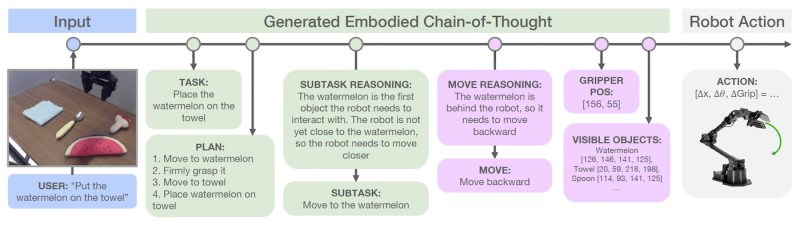
ECoT combines semantic reasoning about tasks and sub-tasks with “embodied” reasoning about the environment and the robot’s state. This includes predicting object bounding boxes, understanding spatial relationships and reasoning about how the robot’s available actions, also called “primitives,” can help achieve the goal.
“Our goals when designing the steps of our embodied chain-of-thought reasoning chains are twofold: encourage the model to (A) reason through the required high-level steps of the task at hand and determine which step needs to be executed next, and (B) increasingly ground this reasoning in lower-level features of the scene and robot state before predicting the robot action,” the researchers write.
To enable VLA models to perform reasoning, the researchers created a pipeline to generate synthetic training data to train VLAs for ECoT reasoning. The process involves using pre-trained object detectors, LLMs, and VLMs to annotate existing robot datasets with information that can be used for reasoning.
They then use Google’s Gemini model to generate the final reasoning chain to accomplish the task. The model first rephrases the given instruction into a more detailed form. It then outlines a sequence of sub-tasks needed to accomplish the main goal. By analyzing the current state of the environment and robot, the model identifies the specific sub-task to focus on. The model generates a natural language command aligned with the chosen sub-task (e.g., “move left,” “grasp the object”). It then predicts the pixel locations of important elements like the robot’s gripper and the bounding boxes of objects in the scene.
The annotated data and reasoning chains are used to train the VLA to obtain ECoT capabilities.
ECoT in action
The researchers evaluated ECoT on a robotic manipulation setup using OpenVLA, which is built on top of Llama-2 7B and the Prismatic VLM.
To create the training examples for ECoT, they ran their data-generation pipeline on the Bridge v2 dataset, which contains more than tens of thousands of trajectories and object interactions on WidowX, a robot arm with six degrees of freedom.
To assess the generalization capabilities of ECoT, the researchers designed a set of tasks that require the robot to handle new objects, scenes, viewpoints and instructions that were not present in the training data.
The results showed that ECoT significantly improved the performance of vanilla OpenVLA, increasing the task success rate by 28% compared to the baseline model. Notably, these improvements were achieved without gathering additional robot training data, which can be expensive and time-consuming.
Beyond the performance gains, the researchers found that ECoT made it much easier to understand why the model failed in certain situations. Since the reasoning steps were expressed in natural language, it was possible to trace back errors and identify the points of failure in the decision-making process.
“Intuitively, training a policy to reason through a task step-by-step in natural language provides a powerful mechanism for humans to interact with the policy and correct its behavior,” the researchers write. “Instead of needing involved teleoperation equipment to provide direct robot action feedback… humans can now simply correct the policy’s behavior by modifying its reasoning chains via natural language feedback.”
ECoT is part of a broader effort to integrate foundation models into robotic control systems. Thanks to their ability to ingest large amounts of unlabeled data from the internet, LLMs and VLMs can fill in many of the gaps that exist in current robotics systems. Foundation models are now being used in different parts of the robotics stack, from designing reward functions to reasoning about the environment and planning actions. It will be interesting to see how the space evolves as the industry moves toward foundation models that are optimized for robotics systems.
